伝統的な(?)言語処理を行うサービスの多くはパイプライン型の処理になっていることが多い。現代においても基礎解析部分はもう見なくなってしまったものの、LLMへの処理含む多段なパイプライン的な処理で機能を構成することは多々ある。
このときにパイプパインを構成する各ステップの解析結果を分析したいケースはよく見られる。特にLLMの文脈においてはLangSmithなどいわゆるLLM observabilityツールを活用して各解析ステップを可視化して分析することはよくあると思う。 これはこれで有用なのだが、ナイーブに使うと実際のサービスで解析結果をトレースしたいと思ったときにいくつか改善したいポイントがある。
- LLMプロバイダーに対するAPI callの結果はトレーシングできるが、API callの外で行われた処理結果はトレースできない。
- マイクロサービスを横断した解析パイプラインの場合、スパンが同じトレースに紐づかない。
- コンプライアンス上、LLM observabilityツールのプロバイダーにデータを送信したくないケースがある。
一方でLLM observabilityツールの多くはOpenTelemetryの枠組みの上にのっかかっていて、これに相乗りすればより一気貫通でトレースデータを分析できるので試してみる。
構成
今回は簡単なサンプルとして、与えられた英語のテキストを要約し、それを日本語に翻訳するというようなユースケースを考えてみる。具体的には以下のようなサービスの構成とする。
- summarization service: テキストを要約するサービス。
- translation service: 英語を日本語に翻訳するサービス
- coordination service: ユーザーからのリクエストを受け付け、各種マイクロサービスとリクエストをやり取りするサービス。
これらに加えてトレースデータを収集, 分析するためにOpenTelemetry collectorとJaegerを使う。
downstreamサービス
summarization serviceとtranslation serviceはdownstreamなサービスになっており、今回はFastAPIとLangChainを使って実装する。
ここではLLM部分のテレメトリーデータの送信はLangSmithにやってもらう。LangSmithでは自社がホストするマネージドサービスにデータ送信するだけでなくセルフホストしたOpenTelemetry Collectorに向けたデータ送信もサポートしている(参考)ので、これを使う。
また、今回はサービスのエンドポイントで受け付けたリクエスト及び返したレスポンスの内容も同時にトレースに含めてみることにした(OpenTelemetryではパフォーマンス上の観点からかセマンティック規約にこの手の情報に対応するattribute名は無い模様)。
具体的な実装はそれぞれ以下のようになる。
Summarization service
import os
from langchain_openai import ChatOpenAIfrom fastapi import FastAPI, Requestimport pydantic
from opentelemetry import tracefrom opentelemetry.instrumentation.fastapi import FastAPIInstrumentorfrom opentelemetry.sdk.trace import TracerProviderfrom opentelemetry.sdk.trace.export import BatchSpanProcessorfrom opentelemetry.exporter.otlp.proto.grpc.trace_exporter import OTLPSpanExporterfrom opentelemetry.sdk.resources import Resource
app = FastAPI()
_otel_collector_endpoint = os.environ.get( "OTEL_EXPORTER_OTLP_ENDPOINT", "http://localhost:4317")
def setup_tracing( app: FastAPI, service_name: str, otel_collector_endpoint: str = _otel_collector_endpoint,): resource = Resource.create( { "service.name": service_name, "service.version": "1.0.0", } )
trace.set_tracer_provider(TracerProvider(resource=resource))
otlp_exporter = OTLPSpanExporter(endpoint=otel_collector_endpoint, insecure=True)
span_processor = BatchSpanProcessor(otlp_exporter) trace.get_tracer_provider().add_span_processor(span_processor)
FastAPIInstrumentor.instrument_app( app, )
class SummarizationRequest(pydantic.BaseModel): text: str
class SummarizationResponse(pydantic.BaseModel): summarized_text: str = pydantic.Field(description="The summarized text")
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0).bind_tools([SummarizationResponse])
@app.post("/summarize")async def summarize(request: SummarizationRequest) -> SummarizationResponse:
current_span = trace.get_current_span() current_span.set_attribute("http.request.body.content", request.model_dump_json())
ret = summarize_text(request.text)
response = SummarizationResponse(summarized_text=ret) current_span.set_attribute("http.response.body.content", response.model_dump_json())
return response
def summarize_text(text: str) -> str: return llm.invoke("Summarize the following text: " + text).tool_calls[0]["args"][ "summarized_text" ]
setup_tracing(app, "summarization-service")Translation service
import os
from langchain_openai import ChatOpenAIfrom fastapi import FastAPIimport pydantic
from opentelemetry import tracefrom opentelemetry.instrumentation.fastapi import FastAPIInstrumentorfrom opentelemetry.sdk.trace import TracerProviderfrom opentelemetry.sdk.trace.export import BatchSpanProcessorfrom opentelemetry.exporter.otlp.proto.grpc.trace_exporter import OTLPSpanExporterfrom opentelemetry.sdk.resources import Resource
app = FastAPI()
_otel_collector_endpoint = os.environ.get( "OTEL_EXPORTER_OTLP_ENDPOINT", "http://localhost:4317")
def setup_tracing( app: FastAPI, service_name: str, otel_collector_endpoint: str = _otel_collector_endpoint,): resource = Resource.create( { "service.name": service_name, "service.version": "1.0.0", } )
trace.set_tracer_provider(TracerProvider(resource=resource))
otlp_exporter = OTLPSpanExporter(endpoint=otel_collector_endpoint, insecure=True)
span_processor = BatchSpanProcessor(otlp_exporter) trace.get_tracer_provider().add_span_processor(span_processor)
FastAPIInstrumentor.instrument_app( app, )
class TranslationRequest(pydantic.BaseModel): text: str
class TranslationResponse(pydantic.BaseModel): translated_text: str = pydantic.Field(description="The translated text in Japanese")
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0).bind_tools([TranslationResponse])
@app.post("/translate")async def translate(request: TranslationRequest) -> TranslationResponse:
current_span = trace.get_current_span() current_span.set_attribute("http.request.body.content", request.model_dump_json())
ret = translate_text(request.text)
response = TranslationResponse(translated_text=ret) current_span.set_attribute("http.response.body.content", response.model_dump_json())
return response
def translate_text(text: str) -> str: return llm.invoke("Translate the following text into Japanese: " + text).tool_calls[ 0 ]["args"]["translated_text"]
setup_tracing(app, "translation-service")Dockerfileとpyproject.tomlは以下のような形
Dockerfile
# Use a Python image with uv pre-installedFROM ghcr.io/astral-sh/uv:python3.12-bookworm-slim
# Install the project into `/app`WORKDIR /app
# Enable bytecode compilationENV UV_COMPILE_BYTECODE=1
# Copy from the cache instead of linking since it's a mounted volumeENV UV_LINK_MODE=copy
# Ensure installed tools can be executed out of the boxENV UV_TOOL_BIN_DIR=/usr/local/bin
# Install the project's dependencies using the lockfile and settingsRUN --mount=type=cache,target=/root/.cache/uv \ --mount=type=bind,source=uv.lock,target=uv.lock \ --mount=type=bind,source=pyproject.toml,target=pyproject.toml \ uv sync --locked --no-install-project --no-dev
# Then, add the rest of the project source code and install it# Installing separately from its dependencies allows optimal layer cachingCOPY . /appRUN --mount=type=cache,target=/root/.cache/uv \ uv sync --locked --no-dev
# Place executables in the environment at the front of the pathENV PATH="/app/.venv/bin:$PATH"
# Reset the entrypoint, don't invoke `uv`ENTRYPOINT []
# Run the FastAPI application by default# Uses `fastapi dev` to enable hot-reloading when the `watch` sync occurs# Uses `--host 0.0.0.0` to allow access from outside the containerCMD ["fastapi", "dev", "--host", "0.0.0.0", "main.py"]pyproject.toml
[project]name = "summarization-service"version = "0.1.0"description = "Add your description here"readme = "README.md"requires-python = ">=3.13"dependencies = [ "fastapi[standard]>=0.116.1", "opentelemetry-api>=1.36.0", "opentelemetry-exporter-otlp>=1.36.0", "opentelemetry-instrumentation-fastapi>=0.57b0", "opentelemetry-sdk>=1.36.0", "langchain>=0.3.27", "langchain-core>=0.3.75", "langchain-openai>=0.3.32", "pydantic>=2.11.7", "langsmith[otel]>=0.4.21",]upstreamサービス
upstreamでリクエストの中継を担うcoordination serviceの実装をする。一気貫通なトレースを行うためにdownstreamなサービスにコンテキストが伝播するようにする必要がある。トレース情報のコンテキスト伝播にはtraceparent, tracestateのHTTPヘッダーが使われていて、HTTPリクエスト用のライブラリに対応するInstrumentationを施す。
import os
from fastapi import FastAPIfrom opentelemetry.instrumentation.fastapi import FastAPIInstrumentorfrom opentelemetry.instrumentation.requests import RequestsInstrumentorimport pydanticimport requests
from opentelemetry import tracefrom opentelemetry.sdk.trace import TracerProviderfrom opentelemetry.sdk.trace.export import BatchSpanProcessorfrom opentelemetry.exporter.otlp.proto.grpc.trace_exporter import OTLPSpanExporterfrom opentelemetry.sdk.resources import Resource
_otel_collector_endpoint = os.environ.get( "OTEL_EXPORTER_OTLP_ENDPOINT", "http://localhost:4317")
def setup_tracing( app: FastAPI, service_name: str, otel_collector_endpoint: str = _otel_collector_endpoint,): resource = Resource.create( { "service.name": service_name, "service.version": "1.0.0", } )
trace.set_tracer_provider(TracerProvider(resource=resource))
otlp_exporter = OTLPSpanExporter(endpoint=otel_collector_endpoint, insecure=True)
span_processor = BatchSpanProcessor(otlp_exporter) trace.get_tracer_provider().add_span_processor(span_processor)
FastAPIInstrumentor.instrument_app( app, )
RequestsInstrumentor().instrument()
app = FastAPI()
_translation_service_endpoint = os.environ["TRANSLATION_SERVICE_ENDPOINT"]_summarization_service_endpoint = os.environ["SUMMARIZATION_SERVICE_ENDPOINT"]
class PredictionRequest(pydantic.BaseModel): text: str
class PredictionResponse(pydantic.BaseModel): prediction: str
@app.post("/predict")async def predict(request: PredictionRequest) -> PredictionResponse:
current_span = trace.get_current_span() current_span.set_attribute("http.request.body.content", request.model_dump_json())
# request to summarization service response = requests.post( _summarization_service_endpoint, json={"text": request.text} ) summarized_text = response.json()["summarized_text"]
# request to translation service response = requests.post( _translation_service_endpoint, json={"text": summarized_text} ) translated_text = response.json()["translated_text"]
response = PredictionResponse(prediction=translated_text) current_span.set_attribute("http.response.body.content", response.model_dump_json())
return response
setup_tracing(app, "coordination-service")OpenTelemetry Collector
トレース情報を待ち受けるCollectorを設定する。今回はJaegerをexporterに設定。
receivers: otlp: protocols: grpc: endpoint: 0.0.0.0:4317 http: endpoint: 0.0.0.0:4318
processors: batch: timeout: 1s send_batch_size: 1024 memory_limiter: check_interval: 1s limit_mib: 256
exporters: debug: verbosity: detailed
otlp/jaeger: endpoint: jaeger:4317 tls: insecure: true
service: pipelines: traces: receivers: [otlp] processors: [memory_limiter, batch] exporters: [debug, otlp/jaeger]サンプルリクエストでトレースの確認
以下のdocker-composeを使って起動する。
services: otel-collector: image: otel/opentelemetry-collector-contrib:latest container_name: otel-collector command: ["--config=/etc/otelcol-contrib/otel-collector.yaml"] volumes: - ./otel-collector.yaml:/etc/otelcol-contrib/otel-collector.yaml:ro ports: - "4317:4317" - "4318:4318" networks: - otel-network restart: unless-stopped healthcheck: test: ["CMD", "curl", "-f", "http://localhost:13133/"] interval: 30s timeout: 10s retries: 3 start_period: 40s
jaeger: image: jaegertracing/all-in-one:latest container_name: jaeger ports: - "16686:16686" - "14250:14250" - "4327:4317" - "4328:4318" environment: - COLLECTOR_OTLP_ENABLED=true - JAEGER_DISABLED=false networks: - otel-network restart: unless-stopped
coordination-service: build: context: ./coordination-service dockerfile: Dockerfile ports: - "8000:8000" environment: - TRANSLATION_SERVICE_ENDPOINT=http://translation-service:8000/translate - SUMMARIZATION_SERVICE_ENDPOINT=http://summarization-service:8000/summarize - OTEL_EXPORTER_OTLP_ENDPOINT=http://otel-collector:4317 networks: - otel-network restart: unless-stopped
summarization-service: build: context: ./summarization-service dockerfile: Dockerfile ports: - "8002:8000" environment: - OPENAI_API_KEY=${OPENAI_API_KEY} - LANGSMITH_TRACING=true - LANGSMITH_OTEL_ENABLED=true - OTEL_EXPORTER_OTLP_ENDPOINT=http://otel-collector:4317 networks: - otel-network restart: unless-stopped
translation-service: build: context: ./translation-service dockerfile: Dockerfile ports: - "8001:8000" environment: - OPENAI_API_KEY=${OPENAI_API_KEY} - LANGSMITH_TRACING=true - LANGSMITH_OTEL_ENABLED=true - OTEL_EXPORTER_OTLP_ENDPOINT=http://otel-collector:4317 networks: - otel-network restart: unless-stopped
networks: otel-network: driver: bridge起動してサンプルリクエストを投げてみる。
$ docker compose up -d$ curl -XPOST --header "Content-Type: application/json" localhost:8000/predict -d'{"text": "OpenAI, Inc. is an American artificial intelligence (AI) organization headquartered in San Francisco, California."}'{"prediction":"OpenAI, Inc.はサンフランシスコに本拠を置くアメリカのAI組織です。"}するとJaegerからトレースが確認できる。summarization-serviceとtranslation-serviceのそれぞれに対するリクエストのスパンも同じトレース上で見つけることができる。
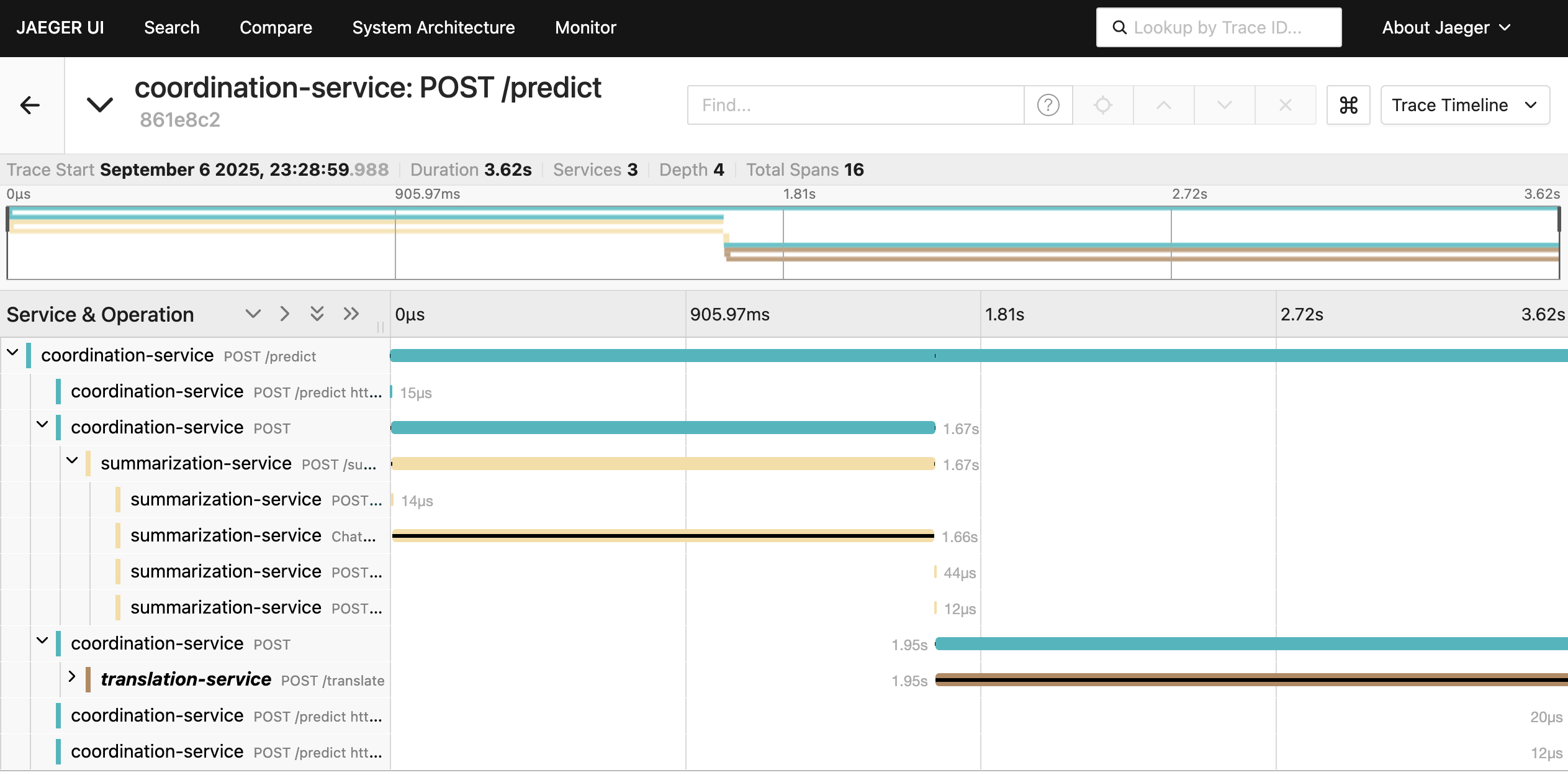 また、各種マイクロサービスへのHTTPリクエストの内容及びOpenAIのLLMの呼び出し内容についても対応するスパンから確認できる。
また、各種マイクロサービスへのHTTPリクエストの内容及びOpenAIのLLMの呼び出し内容についても対応するスパンから確認できる。
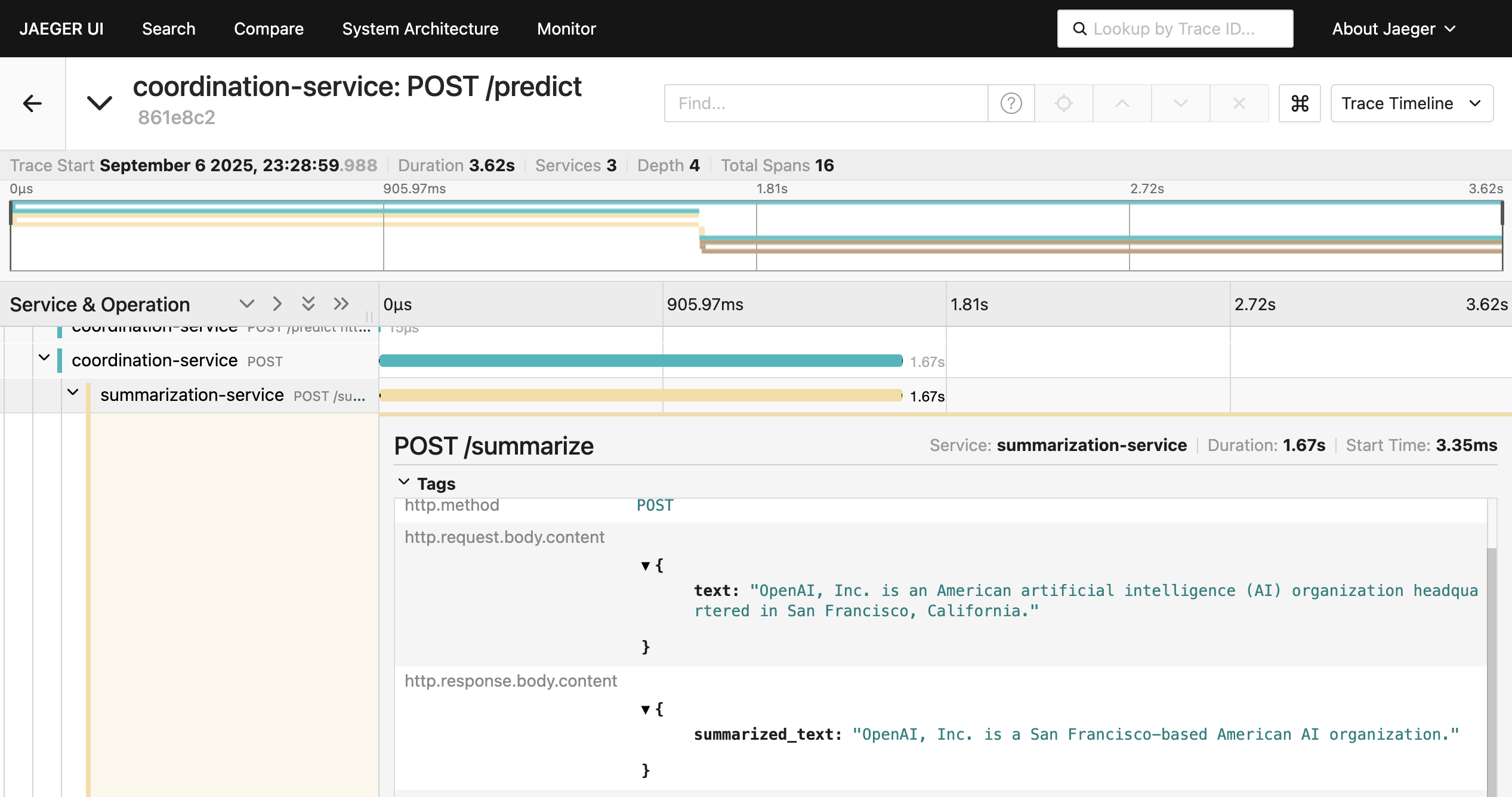
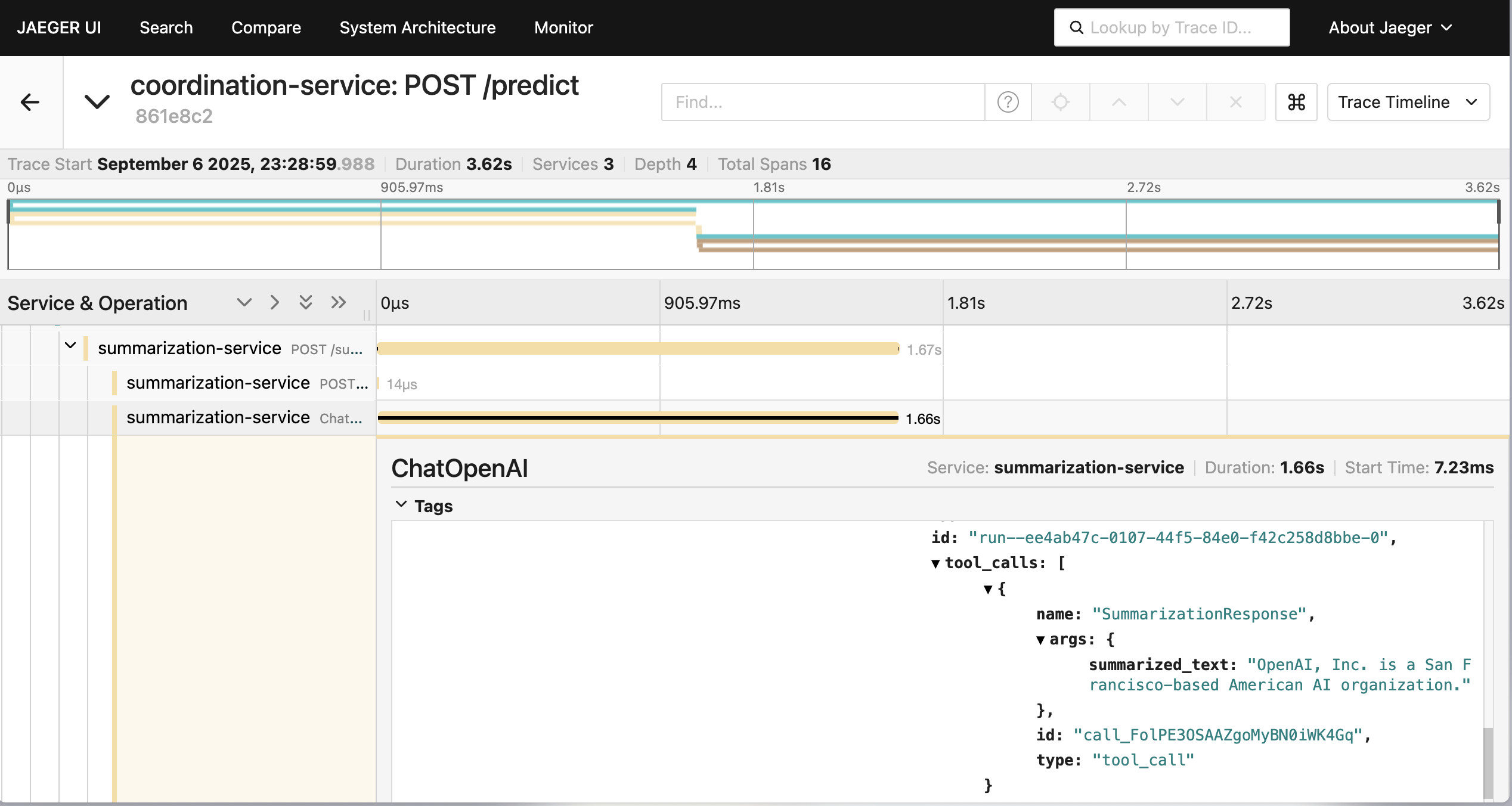 Enjoy tracing life.
Enjoy tracing life.
今回は手動でattributeを設定したりとアプリケーションコード側に手を入れているが、もう少しこれを排除できないか検討したい。最初はenvoy proxy入れてあれこれ試していたが、結局server-to-serverのリクエストを行うときにうまくコンテキスト伝播できずに別々のトレースが作成されてしまっていた。 また、実際にトレースの分析を行う場合は、export先はJaegerではなくOLAPにした方がMLエンジニアが詳細を分析しやすいかもしれない。